Multomodal deep learning - CMU 강의 2.1 Basic Concepts
in Deep Learning on Multimodal
강의 2.1 Basic Concepts에 대한 내용 정리.
Unimodal basic representations & core concept of nueral network
Unimodal basic representation
- Unimodal Classification – Visual Modality
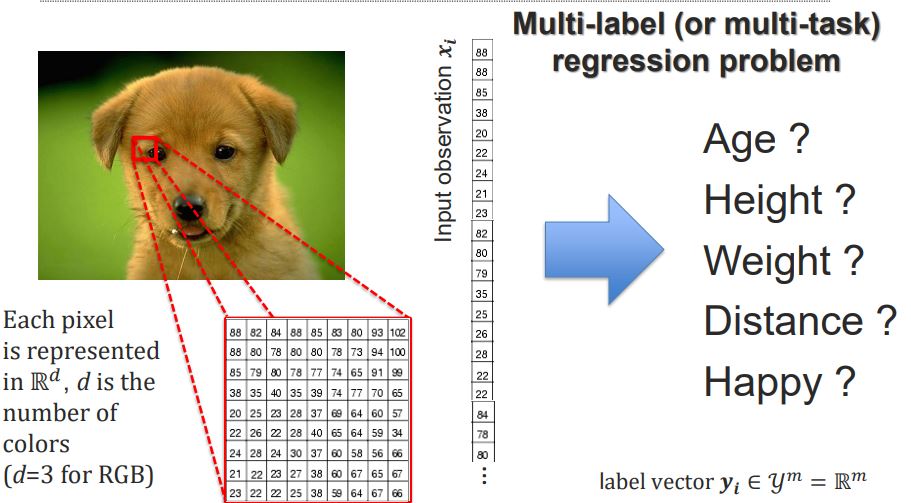
- 이미지가 입력으로 들어모면, 각각의 픽셀들은 RGB 3차원 공간에 표현됨.(Gray scale 이미지는 2차원.)
- 입력 이미지가 Dog이냐? 아니냐? 판단하는 문제는
Binary Classification problem - 입력 이미지가 Dog이냐? Duck이냐? Cat이냐? 를 분류하는 문제는,
Multi-class classification problem - 입력 이미지에 여러 개의 Object가 있다면, {Dog, Bird}이냐? {Dog, Duck}이냐? {Cat, Pig}이냐? 를 분류하는 문제는
Multi-label (or multi-task) classification problem - 입력 이미지의 Object의 Age는? Weight는? 행복해보이는지? 값을 내는 문제는
Multi-label (or multi-task) regression problem - 모델의 입력 값 x는 vector임을 알고있자.
- Unimodal Classification – Language Modality

- Language는 Written language(키보드로 타입핑된 형태)와 Spoken language(대화를 Text로 옮긴것)로 구분됨.
- 쉽게 말하면, paragraph 안에 있는 단어들을 Encode하는 과정.
- Unimodal Classification – Acoustic Modality
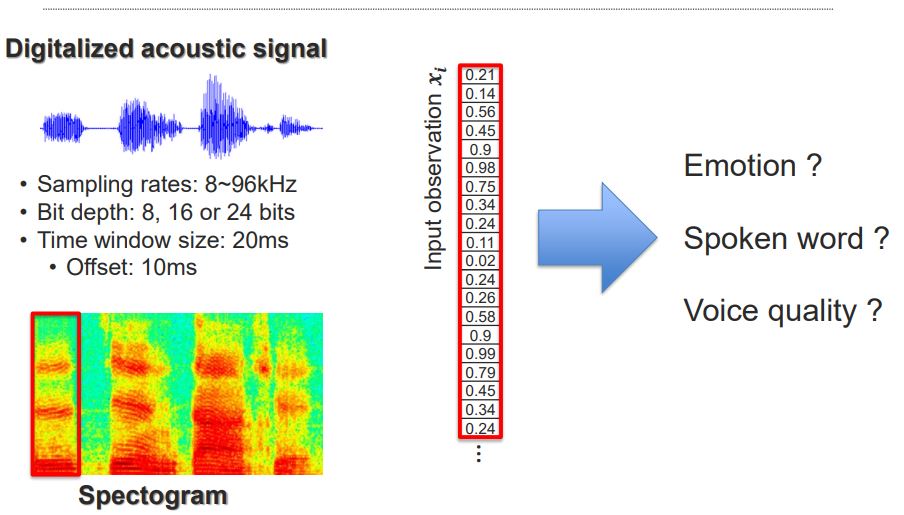
- 음성 신호처리 과정을 설명. Bit depth가 클 수록 more fine-grained한 data를 표현할 수 있음.
- time windows로 어떻게 slice를 하느냐가 중요.
- 얼마나 높은(혹은 낮은) 주파수를 가졌는지는 spectogram을 통해 쉽게 알 수 있음.(y축이 frequency)
- spectogram의 전체를 다 사용하는 것 보다, window 별로 나눠서 처리함.
기타 다른 Unimodal Classification으로는 Graph, set, table을 사용한 것이 있다.
Data-Driven Machine Learning
- Dataset: Collection of labeled samples D:{𝑥_𝑖, 𝑦_𝑖}
- Training: Learn classifier on training set
- Testing: Evaluate classifier on hold-out test set
- Validation: Select optimal hyper-parameters (same size with test set)
Nearest Neighbor Classifier
- Non-parametric approaches—key ideas
- Predict new cases based on similar cases
- Use multiple local models instead of a single global model
- “Distance metrics”를 사용. (L1 or L2 distance)
- 어떤 metric을 쓰지?, K를 어떻게 설정하지? => hyper-parameter 선택
Evaluation methods (for validation and testing)
- Holdout set: The available data set D is divided into two disjoint subsets(training set, test set)
- n-fold cross-validation: The available data is partitioned into n equal-size disjoint subsets.
Linear Classification: Scores and Loss
- 딥러닝 기초는 자세히 설명하진 않겠습니다.(loss function, activation function 등)
- Define a (linear) score function
- Define the loss function (possibly nonlinear)
- Optimization
- 입력 x와 가중치 W를 곱하고 bias항을 더한 함수 f를 사용하여 score를 구할 수 있다.
- Normalize한 후 가장 높은 score를 정답으로 정한 후 label과 비교합니다. -The loss function quantifies the amount by which the prediction scores deviate from the actual values
기계학습, 뉴럴넷에 대한 basic 내용.
