Multomodal deep learning - CMU 강의 4.1 Multimodal Representations
in Deep Learning on Multimodal
강의 4.1 Multimodal Representations에 대한 내용 정리. https://piazza.com/cmu/fall2019/11777/resources
Graph
- Graphs are a general language for describing and modeling complex systems
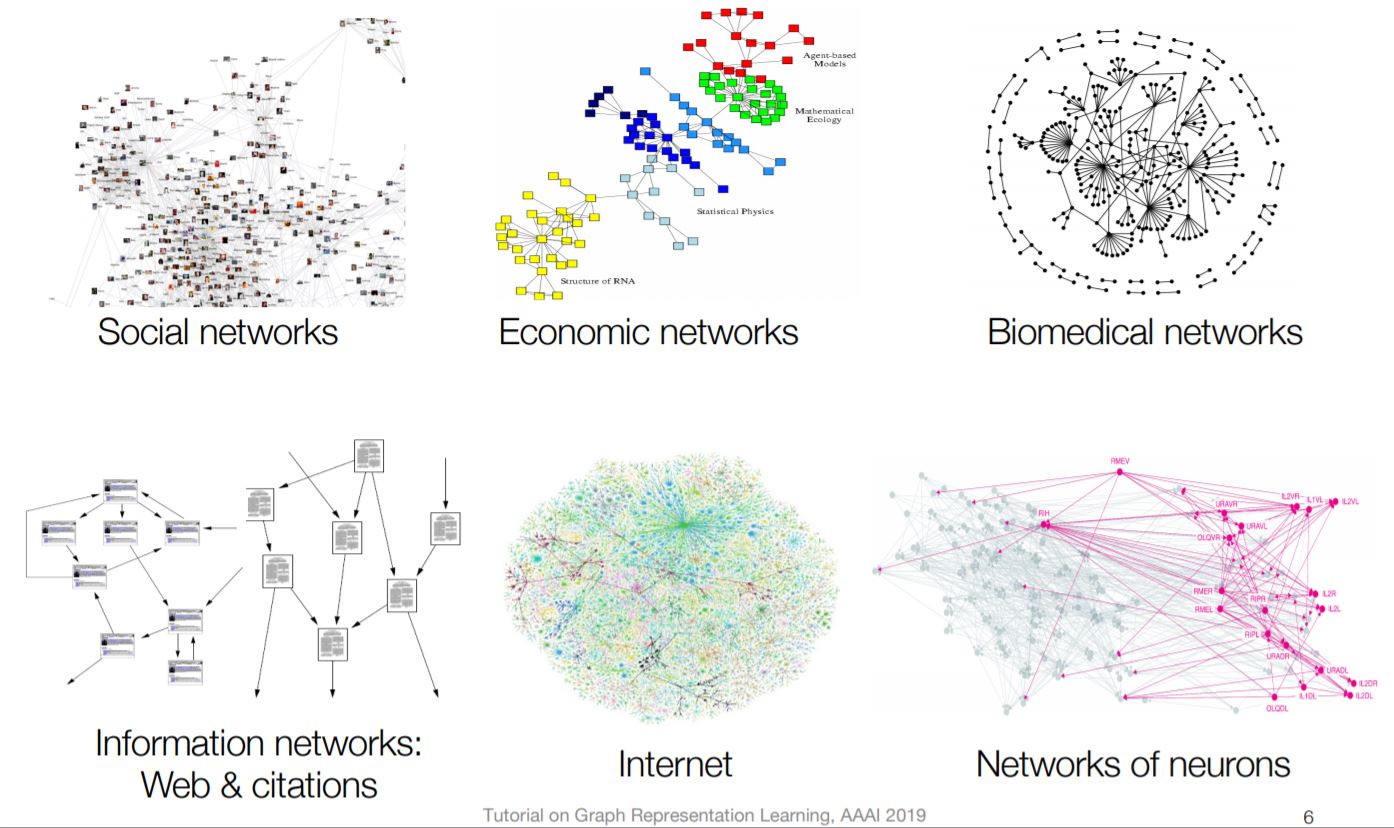
- Supervised Task Goal : Learn from labels associated with a subset of nodes(or with all nodes)
Unsupervised Task Goal : Learn an embedding space where similarity(u,z) ~ Z => graph에서 connect 되어있는 노드는 embedding space에서도 비슷한 위치에 놓여있어야함.
- V is the set of vertices
- A is the binary adjacency matrix
- X is a matrix of node features : text, image 등등
- Y is vector of node labels (optional)
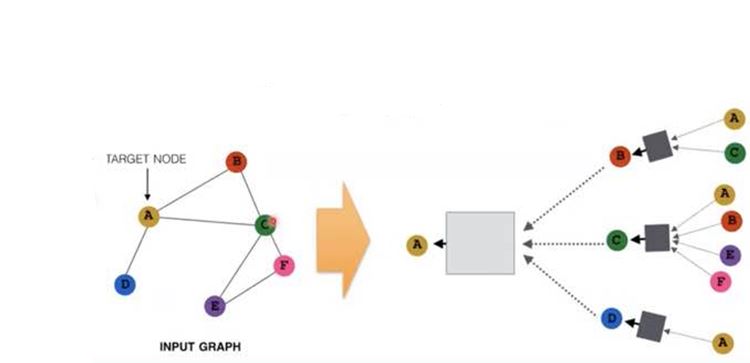
- Key idea : Generate node embeddings based on local neighborhoods in recursive manner
- 노드 하나에서 다른 노드와 relationship이 있는데, 다른 노드들도 자신만의 relationship을 가지고 있음. 이러한 관계를 재귀적인 방법으로 multi-layer로 쌓을 수 있음.
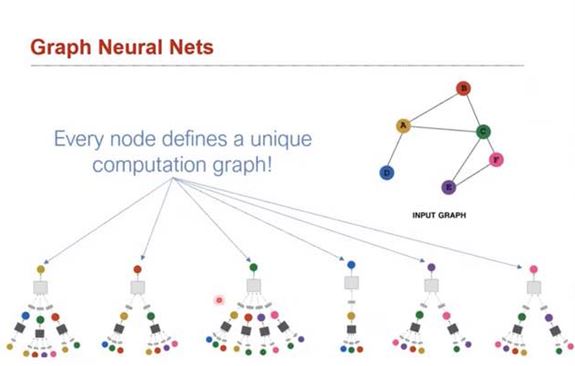
- 각각의 노드는 각자 자신만의 unique computation gragh를 가짐.
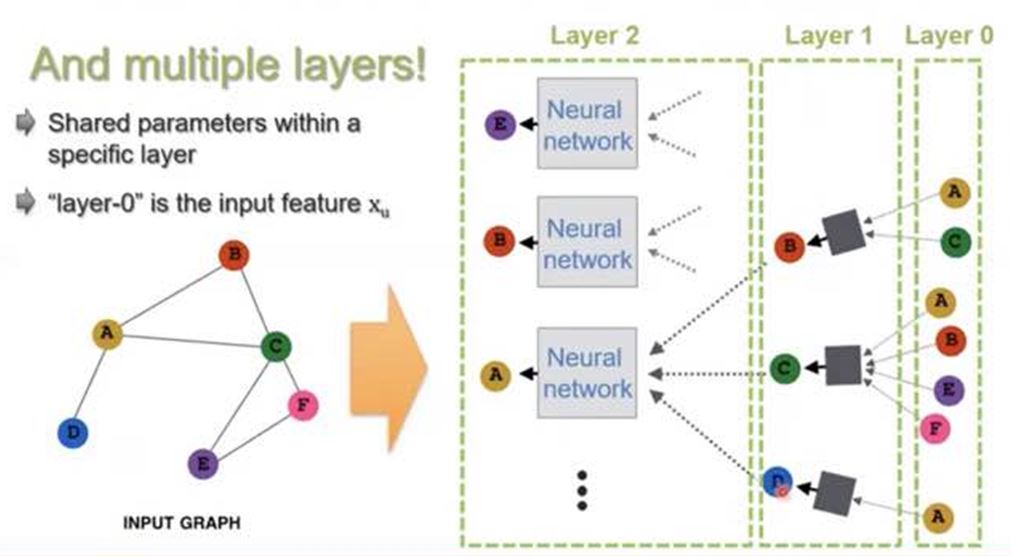
- graph의 layer를 많이 쌓으면 Neural Network와 마찬가지로 gradient vanishing 문제가 발생함.
- 또 하나 중요한 점은 특정 layer에서는 parameter를 갖는 다는것. 다른 layer들과는 share하지 않음.
https://medium.com/watcha/gnn-%EC%86%8C%EA%B0%9C-%EA%B8%B0%EC%B4%88%EB%B6%80%ED%84%B0-%EB%85%BC%EB%AC%B8%EA%B9%8C%EC%A7%80-96567b783479
Multimodal representations
What do we want from multi-modal representation?
- Similarity in that space implies similarity in corresponding concepts
- 다른 모달리티에서 비슷한 개념을 갖는 개체들은 비슷한 representation으로 Embedding 되어야함.
- Useful for various discriminative tasks – retrieval, mapping, fusion etc.
- Possible to obtain in absence of one or more modalities
- Joint representation을 통해, 어느 한 modality가 없는 상황에서도 representation을 구할 수 있다.
- Fill in missing modalities given others (map between modalities)
- translation에서 자주 사용됨. 한 모달리티에서 representation을 통해 다른 모달리티를 얻을 수 있음.
Joint representations과 Coordinated representations
- Joint representations 모달리티들을 하나의 Representaion으로 embedding 시킴.
- Coordinated representations는 각각의 모달리티를 각각의 Representaion으로 embedding 시키고 그 공간들 사이의 관계를 찾음.
- Coordinated representations 스팩트럼 형태로 존재. week <-> strong
- Week coordination => 모달리티들의 공간이 연결되어있지 않음. (seperated spaces)
- Strong coordination => Joint representations과 가까움
Shallow multimodal representations
- Shallow representations do not capture complex relationships
- 서로 다른 두 모달리티의 입력을 concat 한 후 Representation을 얻어냄.
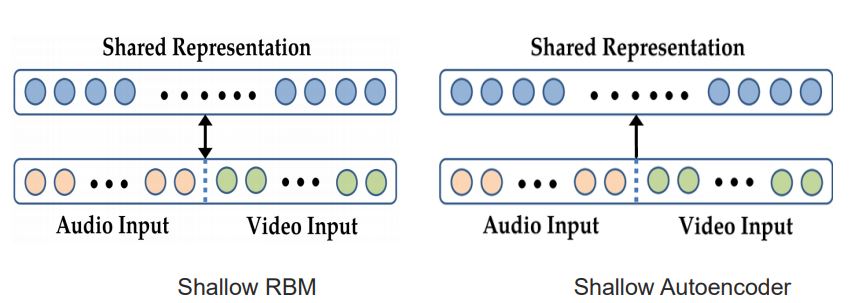
- 특히 요즘은 Autoencoder의 성능이 좋음.
Autoencoder에 대한 설명
- Autoencoder에 대한 설명 생력
- Autoencoder를 multimodal로 적용시키려면? => Joint(Shared) representations
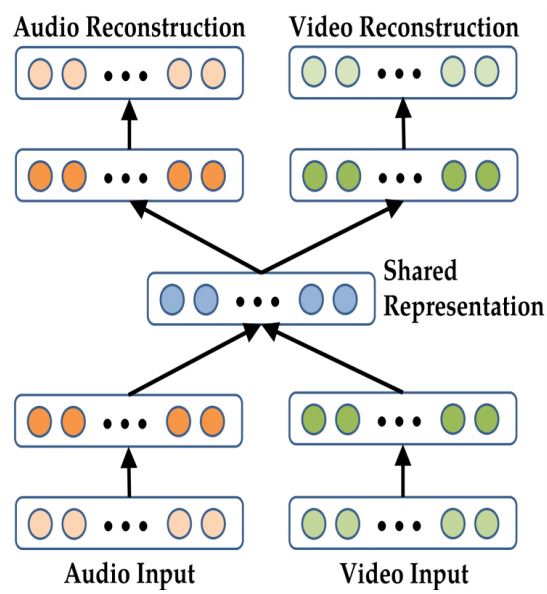
- A bimodal auto-encoder => Used for Audio-visual speech recognition
- To train the model to reconstruct the other modality
- Use both Input.(pre-train)
- Remove audio
- Remove video
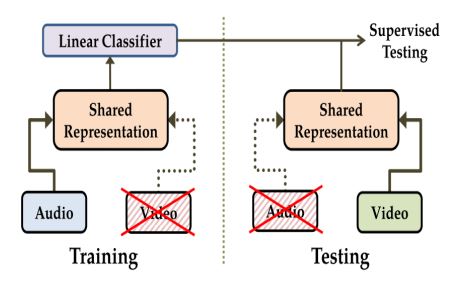
- Use both Input으로 pre-train 시키고 이후에 Audio 만으로 학습을 시킨 상태에서 test는 video만 입력으로 넣어줬을 때 결과 lip reading이 가능했음.
Deep Multimodal Boltzmann machines에 대한 설명
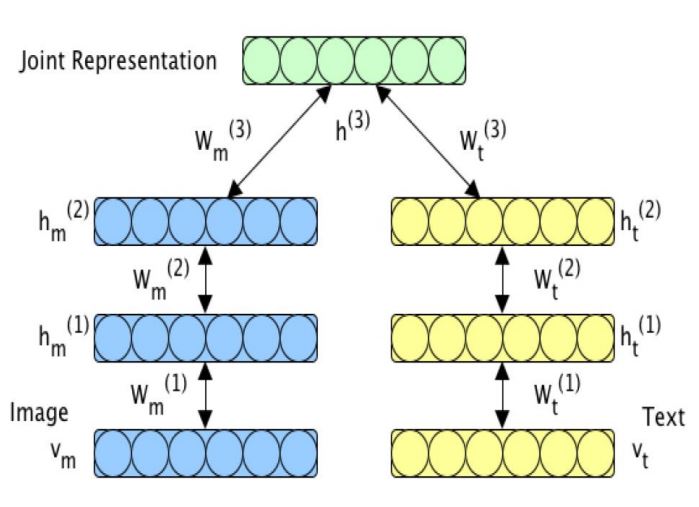
- Generative model
- Multimodal representation trained using Variational approaches
- Used for image tagging and crossmedia retrieval
Analyzing Intermediate Representations
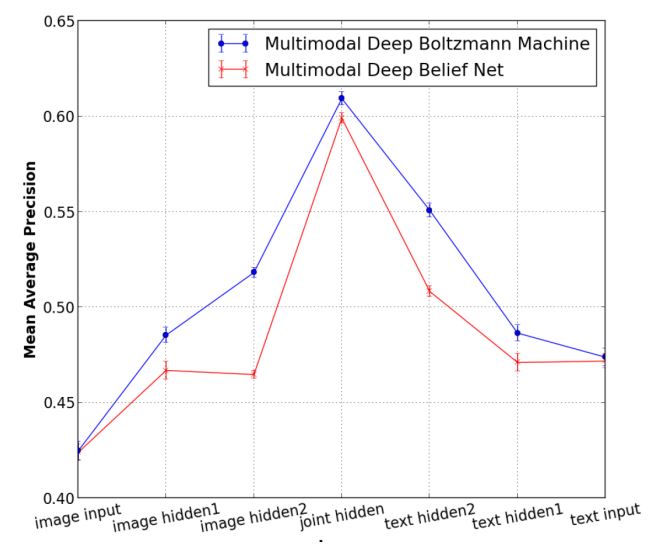
- Joint hidden layer가 가장 정확도가 높았고, 대칭이라는 점이 놀라움. => crossmedia retrieval task에서 multimodal 접근법이 useful 하다는 것을 보여줌.
For supervised learning tasks
- 위에 봤던 것들은 unsupervised task에 사용되는 모델(Autoencoder, DBM)이다.
- For supervised learning tasks, Joining the unimodal representations:
- Simple concatenation
- Element-wise multiplication or summation
- Multilayer perceptron
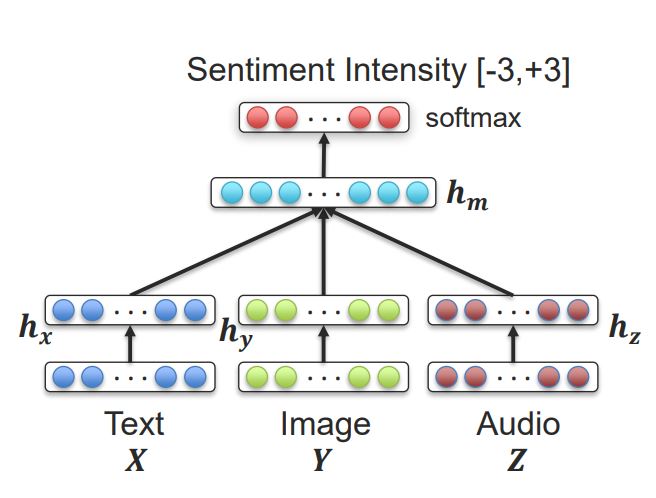
- MOSI dataset에는 text, video, audio 세 가지 모달리티가 포함되어있고, 각각의 sentiment가 어노테이션되어있음.
- 이 세 가지의 모달리티에 대해 Joint representation 과정을 진행(concat or Multilayer perceptron 사용)
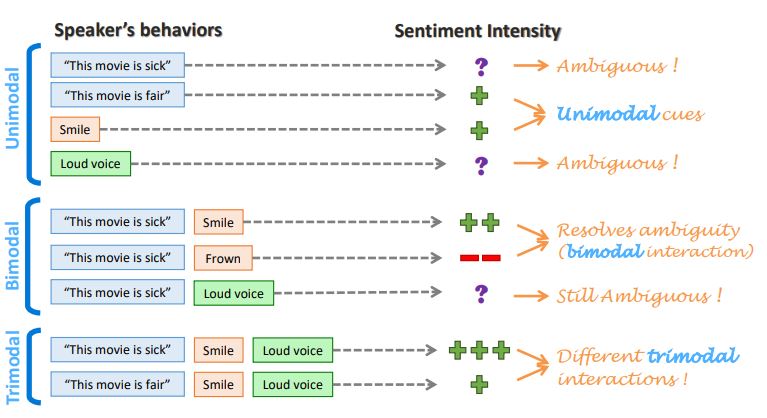
- Unimodal, Bimodal, Trimodal에 대한 차이를 볼 수 있음.
Bilinear Pooling

- h_x와 h_y를 어떻게 합칠까? 에 대한 고민.
- fancier name for the outer product of two vectors. => Bilinear Pooling은 벡터의 외적!
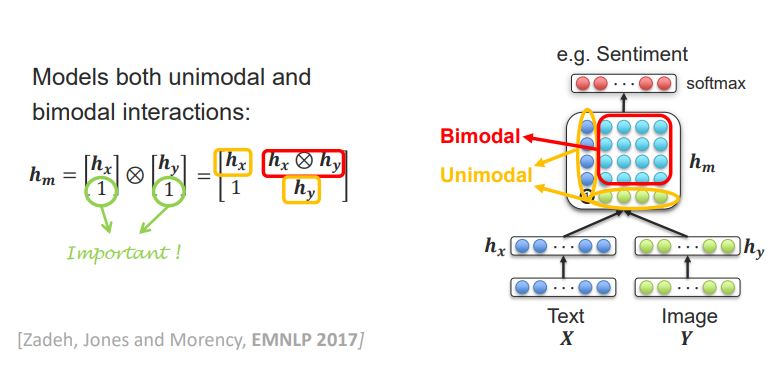
- 조금 더 발전된 방법으로는, 위처럼 외적하기 전에’1’을 추가시켜서 Unimodal한 부분을 만들어 주는 것임.
- 이를 3차원으로 확장시키면, 아래와 같음.
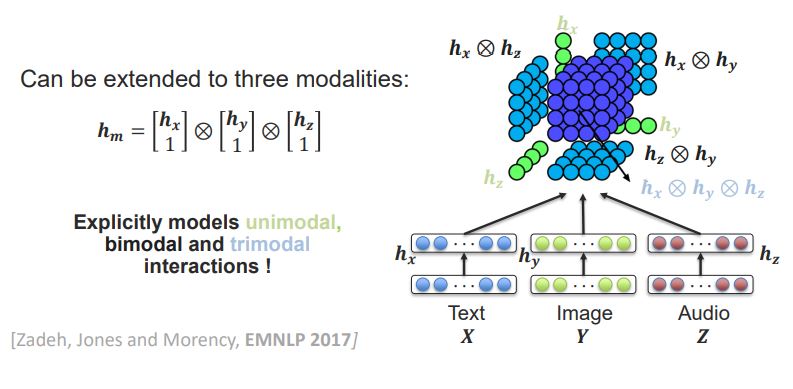
- 물론 이러한 방법은 SOTA임.
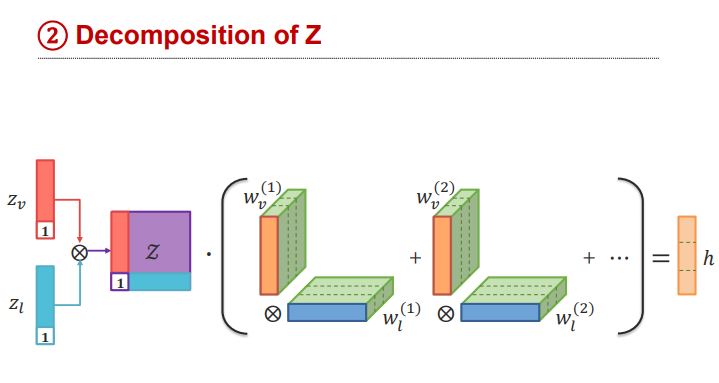
From Tensor Representation to Low-rank Fusion
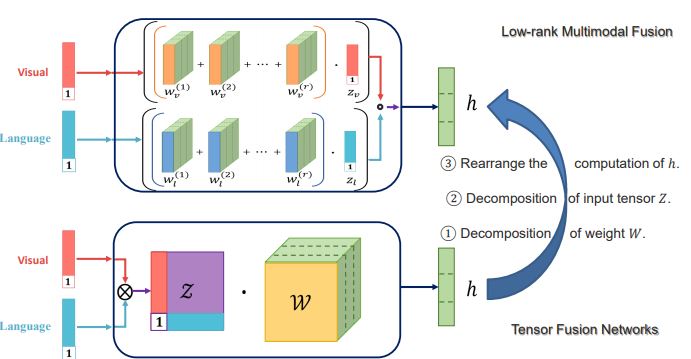
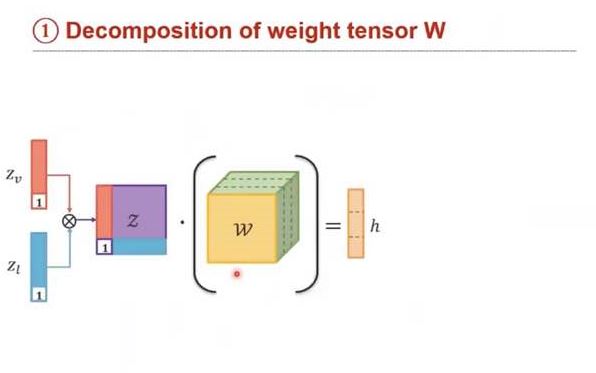
- Tensor Representation을 분해하는 방법을 설명.
- weight 분해
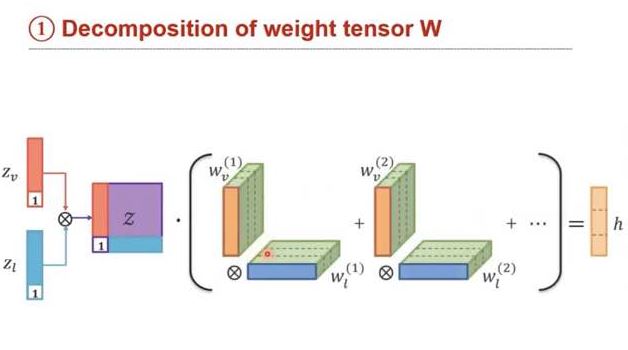
- weight 분해
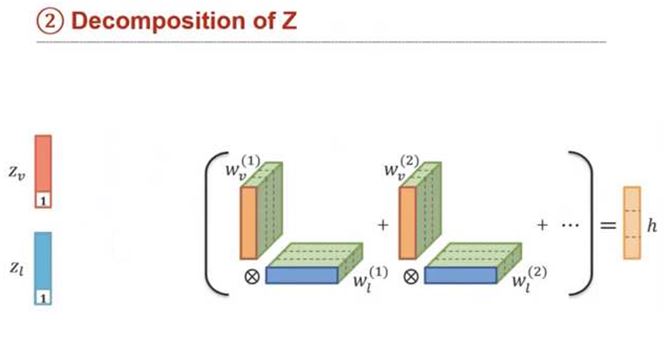
Z를 원래대로 분해
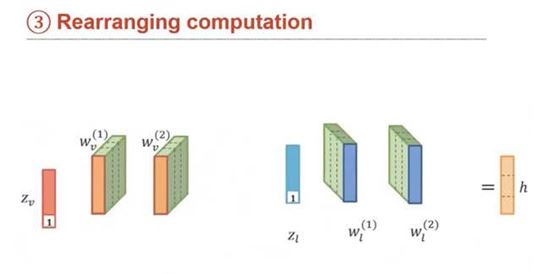
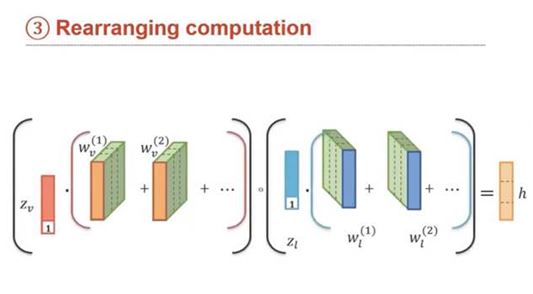
Rearranging computation
Multimodal Encoder-Decoder
- Visual modality often encoded using CNN
- Language modality will be decoded using LSTM
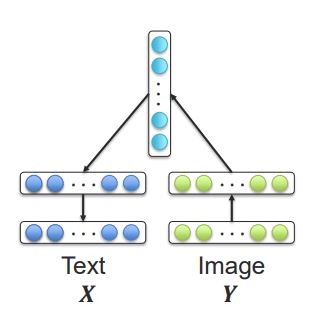
- A simple multilayer perceptron will be used to translate from visual (CNN) to language (LSTM)
Multimodal LSTM에 관한 내용은 skip
- 아직 LSTM 잘 몰라서…ㅠ 추후에 꼭 업데이트 https://youtu.be/37z_tJD81y8
